使用 MinIO 的分散式 HDP Spark 和 Hive
1. 雲原生架構
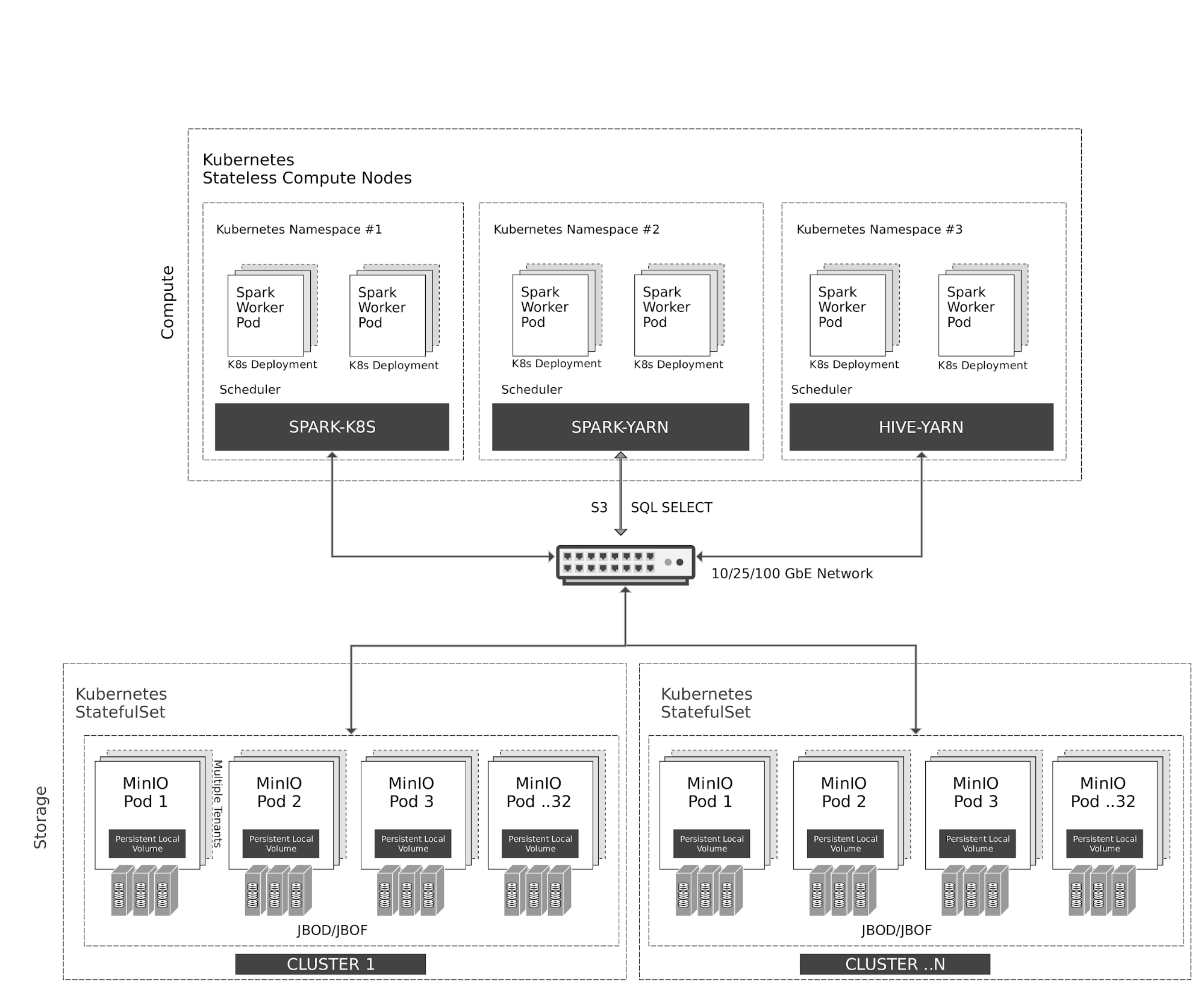
Kubernetes 在運算節點上彈性地管理無狀態的 Spark 和 Hive 容器。Spark 與 Kubernetes 有原生的排程器整合。由於歷史原因,Hive 在 Kubernetes 之上使用 YARN 排程器。
對 MinIO 物件儲存的所有存取均透過 S3/SQL SELECT API 進行。除了運算節點之外,MinIO 容器也由 Kubernetes 作為有狀態容器進行管理,並將本機儲存 (JBOD/JBOF) 對應為持續本機卷。此架構啟用多租戶 MinIO,允許在客戶之間隔離數據。
MinIO 也支援類似於 AWS 區域和層級的多叢集、多站點聯邦。使用 MinIO 資訊生命週期管理 (ILM),您可以將數據設定為在基於 NVMe 的熱儲存和基於 HDD 的溫儲存之間分層。所有數據都使用每個物件金鑰進行加密。租戶之間的存取控制和身分管理由 MinIO 使用 OpenID Connect 或 Kerberos/LDAP/AD 進行管理。
2. 先決條件
使用此指南安裝 Hortonworks 發行版。
使用以下指南之一安裝 MinIO 分散式伺服器。
3. 設定 Hadoop、Spark、Hive 以使用 MinIO
成功安裝後,導覽至 Ambari UI http://<ambari-server>:8080/,並使用預設憑證登入:[使用者名稱:admin,密碼:admin]
3.1 設定 Hadoop
導覽至 Services -> HDFS -> CONFIGS -> ADVANCED,如下所示
導覽至 Custom core-site,以設定 _s3a_ 連接器的 MinIO 參數
sudo pip install yq
alias kv-pairify='yq ".configuration[]" | jq ".[]" | jq -r ".name + \"=\" + .value"'
舉例來說,假設有一組 12 個運算節點,總記憶體為 1.2TiB,我們需要進行以下設定以獲得最佳結果。為 core-site.xml 新增以下最佳項目,以使用 MinIO 設定 s3a。這裡最重要的選項是
cat ${HADOOP_CONF_DIR}/core-site.xml | kv-pairify | grep "mapred"
mapred.maxthreads.generate.mapoutput=2 # Num threads to write map outputs
mapred.maxthreads.partition.closer=0 # Asynchronous map flushers
mapreduce.fileoutputcommitter.algorithm.version=2 # Use the latest committer version
mapreduce.job.reduce.slowstart.completedmaps=0.99 # 99% map, then reduce
mapreduce.reduce.shuffle.input.buffer.percent=0.9 # Min % buffer in RAM
mapreduce.reduce.shuffle.merge.percent=0.9 # Minimum % merges in RAM
mapreduce.reduce.speculative=false # Disable speculation for reducing
mapreduce.task.io.sort.factor=999 # Threshold before writing to drive
mapreduce.task.sort.spill.percent=0.9 # Minimum % before spilling to drive
S3A 是用於連接 S3 和其他相容 S3 的物件儲存服務(如 MinIO)的連接器。MapReduce 工作負載通常以與 HDFS 相同的方式與物件儲存互動。這些工作負載依賴 HDFS 的原子性重新命名功能來完成將資料寫入資料儲存區的動作。物件儲存操作本質上是原子性的,它們不需要/實作重新命名 API。預設的 S3A 提交器透過複製和刪除 API 來模擬重新命名。這種互動模式會因為寫入放大而導致顯著的效能損失。例如,Netflix 開發了兩個新的暫存提交器 - 目錄暫存提交器和分割區暫存提交器 - 以充分利用原生物件儲存操作。這些提交器不需要重新命名操作。這兩個暫存提交器以及另一個名為 Magic 提交器的新增項目都經過評估,用於基準測試。
研究發現,在三個提交器中,目錄暫存提交器是最快的,S3A 連接器應配置以下參數以獲得最佳結果
cat ${HADOOP_CONF_DIR}/core-site.xml | kv-pairify | grep "s3a"
fs.s3a.access.key=minio
fs.s3a.secret.key=minio123
fs.s3a.path.style.access=true
fs.s3a.block.size=512M
fs.s3a.buffer.dir=${hadoop.tmp.dir}/s3a
fs.s3a.committer.magic.enabled=false
fs.s3a.committer.name=directory
fs.s3a.committer.staging.abort.pending.uploads=true
fs.s3a.committer.staging.conflict-mode=append
fs.s3a.committer.staging.tmp.path=/tmp/staging
fs.s3a.committer.staging.unique-filenames=true
fs.s3a.connection.establish.timeout=5000
fs.s3a.connection.ssl.enabled=false
fs.s3a.connection.timeout=200000
fs.s3a.endpoint=http://minio:9000
fs.s3a.impl=org.apache.hadoop.fs.s3a.S3AFileSystem
fs.s3a.committer.threads=2048 # Number of threads writing to MinIO
fs.s3a.connection.maximum=8192 # Maximum number of concurrent conns
fs.s3a.fast.upload.active.blocks=2048 # Number of parallel uploads
fs.s3a.fast.upload.buffer=disk # Use drive as the buffer for uploads
fs.s3a.fast.upload=true # Turn on fast upload mode
fs.s3a.max.total.tasks=2048 # Maximum number of parallel tasks
fs.s3a.multipart.size=512M # Size of each multipart chunk
fs.s3a.multipart.threshold=512M # Size before using multipart uploads
fs.s3a.socket.recv.buffer=65536 # Read socket buffer hint
fs.s3a.socket.send.buffer=65536 # Write socket buffer hint
fs.s3a.threads.max=2048 # Maximum number of threads for S3A
其餘的優化選項將在以下連結中討論
https://hadoop.dev.org.tw/docs/current/hadoop-aws/tools/hadoop-aws/index.html
https://hadoop.dev.org.tw/docs/r3.1.1/hadoop-aws/tools/hadoop-aws/committers.html
套用組態變更後,請繼續重新啟動 Hadoop 服務。
3.2 設定 Spark2
導覽至 Services -> Spark2 -> CONFIGS,如下所示
導覽至「Custom spark-defaults」以設定 _s3a_ 連接器的 MinIO 參數
為 spark-defaults.conf 新增以下最佳項目,以使用 MinIO 設定 Spark。
spark.hadoop.fs.s3a.access.key minio
spark.hadoop.fs.s3a.secret.key minio123
spark.hadoop.fs.s3a.path.style.access true
spark.hadoop.fs.s3a.block.size 512M
spark.hadoop.fs.s3a.buffer.dir ${hadoop.tmp.dir}/s3a
spark.hadoop.fs.s3a.committer.magic.enabled false
spark.hadoop.fs.s3a.committer.name directory
spark.hadoop.fs.s3a.committer.staging.abort.pending.uploads true
spark.hadoop.fs.s3a.committer.staging.conflict-mode append
spark.hadoop.fs.s3a.committer.staging.tmp.path /tmp/staging
spark.hadoop.fs.s3a.committer.staging.unique-filenames true
spark.hadoop.fs.s3a.committer.threads 2048 # number of threads writing to MinIO
spark.hadoop.fs.s3a.connection.establish.timeout 5000
spark.hadoop.fs.s3a.connection.maximum 8192 # maximum number of concurrent conns
spark.hadoop.fs.s3a.connection.ssl.enabled false
spark.hadoop.fs.s3a.connection.timeout 200000
spark.hadoop.fs.s3a.endpoint http://minio:9000
spark.hadoop.fs.s3a.fast.upload.active.blocks 2048 # number of parallel uploads
spark.hadoop.fs.s3a.fast.upload.buffer disk # use disk as the buffer for uploads
spark.hadoop.fs.s3a.fast.upload true # turn on fast upload mode
spark.hadoop.fs.s3a.impl org.apache.hadoop.spark.hadoop.fs.s3a.S3AFileSystem
spark.hadoop.fs.s3a.max.total.tasks 2048 # maximum number of parallel tasks
spark.hadoop.fs.s3a.multipart.size 512M # size of each multipart chunk
spark.hadoop.fs.s3a.multipart.threshold 512M # size before using multipart uploads
spark.hadoop.fs.s3a.socket.recv.buffer 65536 # read socket buffer hint
spark.hadoop.fs.s3a.socket.send.buffer 65536 # write socket buffer hint
spark.hadoop.fs.s3a.threads.max 2048 # maximum number of threads for S3A
套用組態變更後,請繼續重新啟動 Spark 服務。
3.3 設定 Hive
導覽至 Services -> Hive -> CONFIGS -> ADVANCED,如下所示
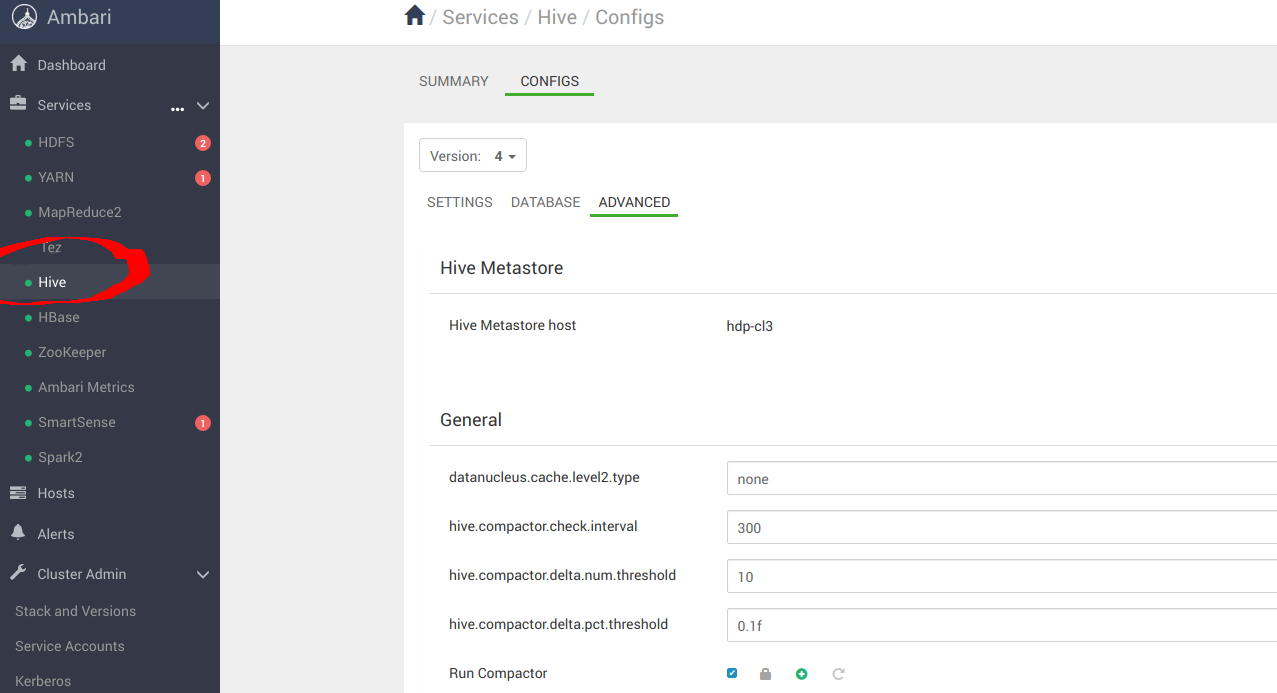
導覽至「Custom hive-site」以設定 _s3a_ 連接器的 MinIO 參數
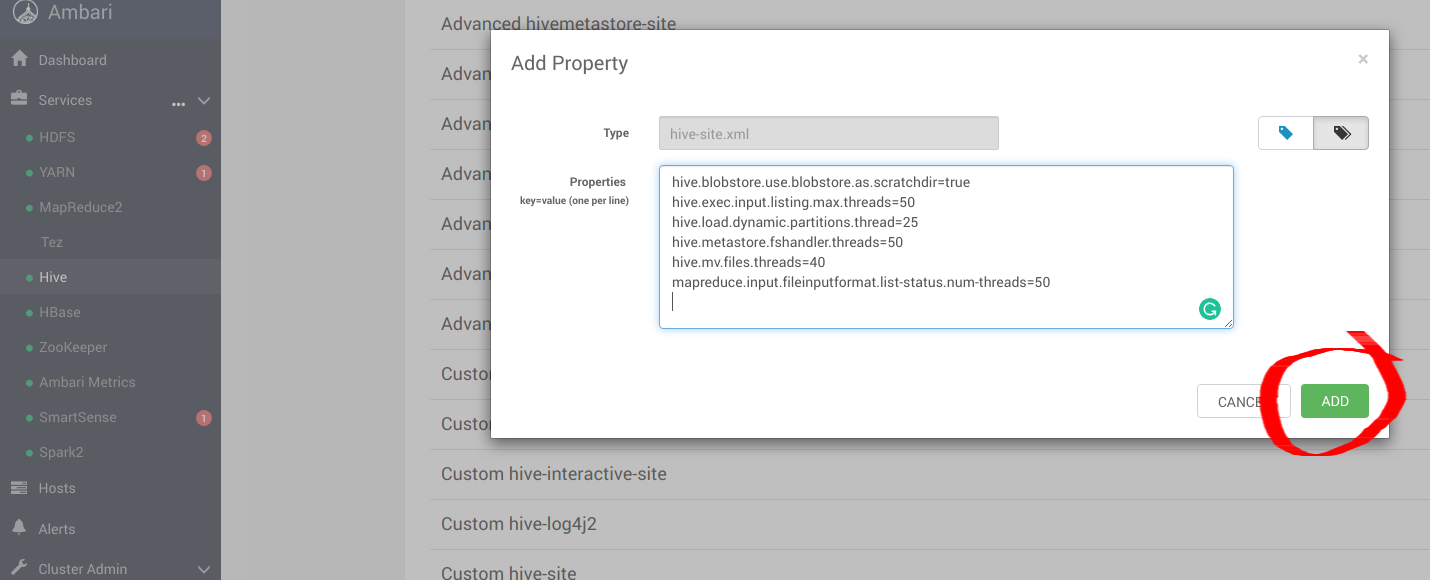
為 hive-site.xml 新增以下最佳項目,以使用 MinIO 設定 Hive。
hive.blobstore.use.blobstore.as.scratchdir=true
hive.exec.input.listing.max.threads=50
hive.load.dynamic.partitions.thread=25
hive.metastore.fshandler.threads=50
hive.mv.files.threads=40
mapreduce.input.fileinputformat.list-status.num-threads=50
如需更多關於這些選項的資訊,請造訪 https://www.cloudera.com/documentation/enterprise/5-11-x/topics/admin_hive_on_s3_tuning.html
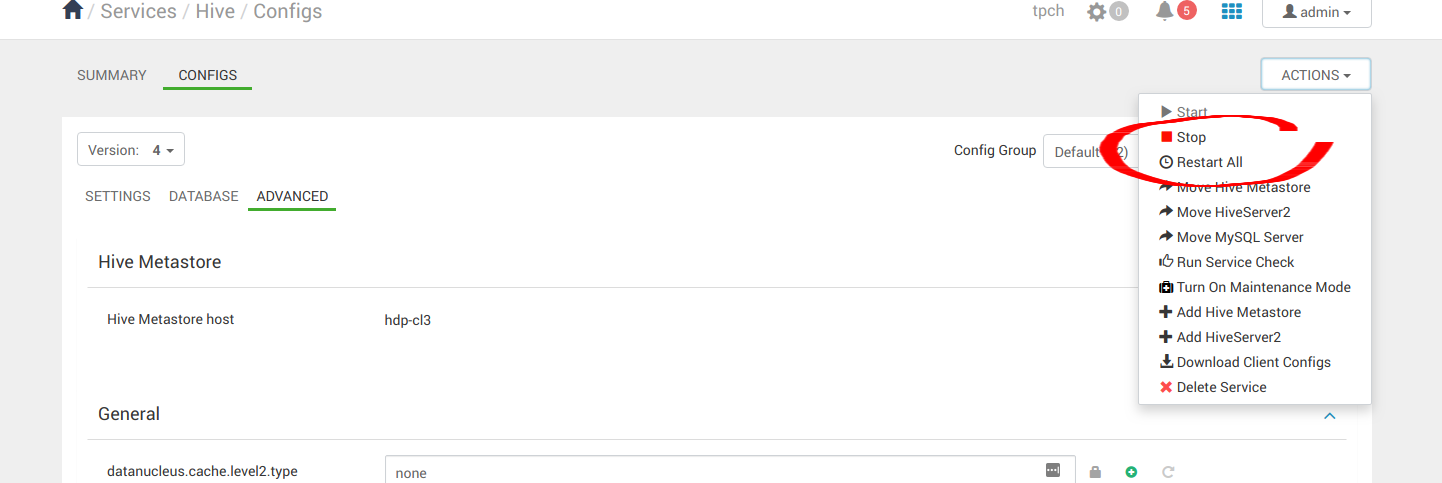
套用組態變更後,請繼續重新啟動所有 Hive 服務。
4. 執行範例應用程式
成功安裝 Hive、Hadoop 和 Spark 後,我們現在可以繼續執行一些範例應用程式,以查看它們是否配置正確。我們可以利用 Spark Pi 和 Spark WordCount 程式來驗證我們的 Spark 安裝。我們還可以探索如何從命令列和 Spark Shell 執行 Spark 工作。
4.1 Spark Pi
透過執行以下運算密集型範例來測試 Spark 安裝,該範例透過向一個圓形「投擲飛鏢」來計算 pi。該程式在單位正方形((0,0) 到 (1,1))中產生點,並計算有多少點落在正方形內的單位圓內。結果會逼近 pi。
按照以下步驟執行 Spark Pi 範例
以使用者 ‘spark’ 登入。
當工作執行時,函式庫現在可以在中間處理期間使用 MinIO。
導覽至具有 Spark 用戶端的節點,並存取 spark2-client 目錄
cd /usr/hdp/current/spark2-client
su spark
使用 org.apache.spark 中的程式碼,在 yarn-client 模式下執行 Apache Spark Pi 工作
./bin/spark-submit --class org.apache.spark.examples.SparkPi \
--master yarn-client \
--num-executors 1 \
--driver-memory 512m \
--executor-memory 512m \
--executor-cores 1 \
examples/jars/spark-examples*.jar 10
該工作應產生如下所示的輸出。請注意輸出中的 pi 值。
17/03/22 23:21:10 INFO DAGScheduler: Job 0 finished: reduce at SparkPi.scala:38, took 1.302805 s
Pi is roughly 3.1445191445191445
也可以在瀏覽器中檢視工作狀態,方法是導覽至 YARN ResourceManager Web UI 並點擊工作歷史伺服器資訊。
4.2 WordCount
WordCount 是一個簡單的程式,用於計算文字檔案中單字出現的頻率。程式碼會建立一個稱為計數的 (String, Int) 對資料集,並將該資料集儲存到檔案中。
以下範例將 WordCount 程式碼提交至 Scala Shell。為 Spark WordCount 範例選擇一個輸入檔案。我們可以將任何文字檔案作為輸入。
以使用者 ‘spark’ 登入。
當工作執行時,函式庫現在可以在中間處理期間使用 MinIO。
導覽至具有 Spark 用戶端的節點,並存取 spark2-client 目錄
cd /usr/hdp/current/spark2-client
su spark
以下範例使用 log4j.properties 作為輸入檔案
4.2.1 將輸入檔案上傳到 HDFS:
hadoop fs -copyFromLocal /etc/hadoop/conf/log4j.properties
s3a://testbucket/testdata
4.2.2 執行 Spark Shell:
./bin/spark-shell --master yarn-client --driver-memory 512m --executor-memory 512m
該命令應產生如下所示的輸出。(帶有額外的狀態訊息)
Spark context Web UI available at http://172.26.236.247:4041
Spark context available as 'sc' (master = yarn, app id = application_1490217230866_0002).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.1.0.2.6.0.0-598
/_/
Using Scala version 2.11.8 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_112)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
在 scala> 提示符下,輸入以下命令來提交工作,將節點名稱、檔案名稱和檔案位置替換為您的值
scala> val file = sc.textFile("s3a://testbucket/testdata")
file: org.apache.spark.rdd.RDD[String] = s3a://testbucket/testdata MapPartitionsRDD[1] at textFile at <console>:24
scala> val counts = file.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey(_ + _)
counts: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[4] at reduceByKey at <console>:25
scala> counts.saveAsTextFile("s3a://testbucket/wordcount")
使用以下其中一種方法來檢視工作輸出
在 Scala Shell 中檢視輸出
scala> counts.count()
364
若要從 MinIO 檢視輸出,請離開 Scala Shell。檢視 WordCount 工作狀態
hadoop fs -ls s3a://testbucket/wordcount
輸出應與以下類似
Found 3 items
-rw-rw-rw- 1 spark spark 0 2019-05-04 01:36 s3a://testbucket/wordcount/_SUCCESS
-rw-rw-rw- 1 spark spark 4956 2019-05-04 01:36 s3a://testbucket/wordcount/part-00000
-rw-rw-rw- 1 spark spark 5616 2019-05-04 01:36 s3a://testbucket/wordcount/part-00001